

Hello creators 🙌
[1-5] openpyxl, Workbook 활용해서 파이썬으로 엑셀 다루기 (feat. 스파르타 코딩클럽 데이터 분석 수업) 본문
[WEB & AI] (feat. 취준)/Python
[1-5] openpyxl, Workbook 활용해서 파이썬으로 엑셀 다루기 (feat. 스파르타 코딩클럽 데이터 분석 수업)
부시매나_HA 2022. 12. 10. 10:37728x90
반응형
Study Colab URL
https://colab.research.google.com/drive/1coeNsJQ7EH-J-ZxL3XCECYPFGqkVZ1a3#scrollTo=P4L2IHWQjB_z
스파르타코딩_국비_데이터분석.ipynb의 사본
Colaboratory notebook
colab.research.google.com
openpyxl 라이브러리 설치
!pip install openpyxl
#라이브러리 설치
# 이렇게 쓰면 된다~ 하는 'document' 가 있었을 것
# 이게 '코드 스니펫' 으로 들어감
A1 셀에 안녕하세요 넣기
from openpyxl import Workbook # openpyxl 라이브러리 중에서 Workbook 함수? 클래스? 를 임포트
wb= Workbook() # workbook 함수, 클래스? 를 > wb 라고 부를거야
sheet = wb.active # wb라는 함수, 클래스 중 > active 라는 함수? 를 쓸거야 > 그러면 활성화된(active된 sheet가 나옴) > 이걸 sheet 에 넣을거야.
sheet['A1'] = '안녕하세요!' # (위에서) 만들어진 sheet 의 AI 셀에 '안녕하세요' 를 넣어라
wb.save("샘플파일.xlsx") # 샘플 파일 이라는 파일로 저장해라
wb.close()
# 왼쪽 탭 열어서 > 해당 파일, '더블클릭' 하면 > 폴더가 다운 받아짐!
스파르타코딩_국비_데이터분석.ipynb의 사본
Colaboratory notebook
colab.research.google.com
반응형
'샘플 파일' 다운 받아서 아래와 같이 수정

수정한 파일 업로드 하기

엑셀 읽기
# 엑셀 읽기
import openpyxl # 라이브러리 가져올거야
wb = openpyxl.load_workbook('샘플파일임.xlsx') # 라이브러리에서 load_wordkbook 써서 > 해당 엑셀 파일 열거야 > 그리고 wb 에 담을거야
sheet = wb['Sheet'] # ❓ 엑셀 파일 (xlsx) 을 > 이 라이브러리가 알아들을 수 있게 sheet 로 변환?
print(sheet['A1'].value) # 해당 sheet 중 A1 셀에 있는 값을 호출
print(sheet['B1'].value) # 해당 sheet 중 A1 셀에 있는 값을 호출
row 이용해서 편하게 읽기
# rows 이용해서 편하게 읽기
# 엑셀 읽기
import openpyxl # 라이브러리 가져올거야
wb = openpyxl.load_workbook('샘플파일임.xlsx') # 라이브러리에서 load_wordkbook 써서 > 해당 엑셀 파일 열거야 > 그리고 wb 에 담을거야
sheet = wb['Sheet'] # ❓ 엑셀 파일 (xlsx) 을 > 이 라이브러리가 알아들을 수 있게 sheet 로 변환?
rows = sheet.rows # rows 의 기능 : sheet 에 있는 '모든 행의 값'⭐ 들을 가져온다.
# print(rows)
# [다 담겨있는 거에서 > 하나씩 빼서 출력하기]
for row in rows:
print(row[0].value, row[1].value, row[2].value ) # row 변수에 담겨진 '값' 을 호출한다.
list 사용해서 '맨 윗줄' 부터 나오게 하기
# list 를 사용해서 > '맨 윗줄' 부터 나오게 하기
import openpyxl
wb = openpyxl.load_workbook('샘플파일임.xlsx') # ✅ 여기 파일 이름 체크 할 것 / error 가능한 지점
sheet = wb['Sheet']
rows = list(sheet.rows)[1:] # row값들을 리스트로 만든다 > 첫 번째 리스트 부터 주루룩 가져온다.
# 거의 이렇게 많이 사용함 ⭐⭐⭐⭐⭐
for row in rows:
print(row[0].value, row[1].value, row[2].value) #0번째 셀 고른것에서 > value! 를 달라 , 이걸 해야 값이 나옴
가격이 300원 보다 작은애들만 보기
# 가격이 300원 보다 작은 애들만 보기
import openpyxl
wb = openpyxl.load_workbook('샘플파일임.xlsx') # ✅ 여기 파일 이름 체크 할 것 / error 가능한 지점
sheet = wb['Sheet']
rows = list(sheet.rows)[1:] # row값들을 리스트로 만든다 > 첫 번째 리스트 부터 주루룩 가져온다.
# 거의 이렇게 많이 사용함 ⭐⭐⭐⭐⭐
for row in rows:
if row[2].value < 300 : # '가격' 은 row[2] 에 있음. > 그 가격의 value 를 꺼내서 본다 > 그게 300 보다 작으면 > 아래줄을 실행한다.
# [새롭게 느낀점] 가격이 row[2] 에 있다는 것! ⭐
# 이렇게, sequence 로, what's next 로 이해하면 된다. ⭐⭐⭐⭐⭐
print(row[2].value) # 300원 보다 적을 때의 '가격' 이 나오겠지
⭐ 위의 결과를 응용해서 > '삼성전자' 뉴스 스크래핑 한것을 > '삼성전자 엑셀 파일' 로 저장하기_part1
# 위의 결과를 응용해서 > '삼성전자' 뉴스 스크래핑 한것을 > '삼성전자 엑셀 파일' 로 저장하기
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
def get_news(keyword):
wb= Workbook() # openpyxl 라이브러리 中 Workbook 함수?클래스? 를 > wb 라고 부를거야
sheet = wb.active # wb 中 active 함수를 > sheet 에 담아 (❓ 담아? 함수를? )
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# headers 는 모르겠네 😥😥❓❓
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
# 내가 특정 주소의 keyword 를 넣으면 > 해당 주소에 대한 keyword 에 대해서 'HTML, CSS, Javascript' 를 요청❓ > 이걸 get 해 > 그리고 data 에 담아
soup = BeautifulSoup(data.text, 'html.parser') # 받아온 data 에서 text 만 꺼내❓ > html 로 분석할 수 있게 해❓ > 그걸 soup 에 담아
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
# 분석할 수 있는 soup 에 > select 함수를 넣어서 분석하고 싶은 애들 css selector 로 골라와 > 그리고 lis 에 넣어
# 이제 그러면 lis 에는 li 들이 리스트 형태로, 덩어리 째로 들어가게 됨 ⭐⭐⭐⭐⭐
# [생각] li 까지 내려갔을 때 > li 들이, 리스트로 있어서, for 문을 쓸 수 있다는게 중요. / 아직 100% 이해는 안 돼 📛 /
# for 문 사용해서 가져오기
for li in lis: # li 리스트 덩어리 중 > 하나씩 꺼내올거야
a = li.select_one('a.news_tit') # 하나 꺼내온 li 에서 > class 이름이 new_tit 인것을 찾아서 > 그 부분을 a 에 담아
print(a.text, a['href']) # a 중에서 text, 링크 주소를 꺼내서 프린트 해줘
wb.save(f'{keyword}.xlsx') # 지금까지 만들어진걸 excel로 만든다.
wb.close() # 종료❓ / 왜 있는지는 모르겠음.
get_news ('삼성전자')
스파르타코딩_국비_데이터분석.ipynb의 사본
Colaboratory notebook
colab.research.google.com
⭐ 위의 결과를 응용해서 > '삼성전자' 뉴스 스크래핑 한것을 > '삼성전자 엑셀 파일' 로 저장하기_part2
# 위의 결과를 응용해서 > '삼성전자' 뉴스 스크래핑 한것을 > '삼성전자 엑셀 파일' 로 저장하기_part2
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
def get_news(keyword):
wb= Workbook() # openpyxl 라이브러리 中 Workbook 함수?클래스? 를 > wb 라고 부를거야
sheet = wb.active # wb 中 active 함수를 > sheet 에 담아 (❓ 담아? 함수를? )
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# headers 는 모르겠네 😥😥❓❓
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
# 내가 특정 주소의 keyword 를 넣으면 > 해당 주소에 대한 keyword 에 대해서 'HTML, CSS, Javascript' 를 요청❓ > 이걸 get 해 > 그리고 data 에 담아
soup = BeautifulSoup(data.text, 'html.parser') # 받아온 data 에서 text 만 꺼내❓ > html 로 분석할 수 있게 해❓ > 그걸 soup 에 담아
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
# 분석할 수 있는 soup 에 > select 함수를 넣어서 분석하고 싶은 애들 css selector 로 골라와 > 그리고 lis 에 넣어
# 이제 그러면 lis 에는 li 들이 리스트 형태로, 덩어리 째로 들어가게 됨 ⭐⭐⭐⭐⭐
# [생각] li 까지 내려갔을 때 > li 들이, 리스트로 있어서, for 문을 쓸 수 있다는게 중요. / 아직 100% 이해는 안 돼 📛 /
# for 문 사용해서 가져오기
for li in lis: # li 리스트 덩어리 중 > 하나씩 꺼내올거야
a = li.select_one('a.news_tit') # 하나 꺼내온 li 에서 > class 이름이 new_tit 인것을 찾아서 > 그 부분을 a 에 담아
row = [a.text, a['href']] # a 중에서 text, 링크 주소를 꺼내줘 > 이걸 리스트에 담아 / ⭐ 이 부분이 바뀌었음
sheet.append(row) # row 를 line9 에서 만들어진 sheet 에 붙여넣는다. ⭐⭐⭐
# 위에는 print 를 했는데, 여기가 'excel' 에 넣는 순간임 ⭐⭐⭐
wb.save(f'{keyword}.xlsx') # 지금까지 만들어진걸 excel로 만든다.
wb.close() # 종료❓ / 왜 있는지는 모르겠음.
get_news ('삼성전자') # 만든 함수 실행
get_news ('현대자동차')
datetime 라이브러리 이용해서 '날짜로된 폴더' 만들기
# datetime 라이브러리 이용해서 '날짜로된 폴더' 만들기
from datetime import datetime # date time 라이브러리를 가져와서 > 그 중에서 dateime 함수(클래스?) 를 쓸거야
a = datetime.today().strftime("%Y-%m-%d") # 그 함수(클래스?) 中 today 함수 로 현재 시간을 가져오고 > 그걸 string 으로 바꿀 거야
# 이때, - 를 쓸 수도 있고, / 를 쓸 수도 있어
print(a)
# cf. string 을 _ 로 쓰는 경우
b = datetime.today().strftime("%Y_%m_%d") # ✅ 여기에서 / 로 썼어~
print(b)
⭐⭐⭐ 위의 결과를 응용해서 > '삼성전자' 뉴스 스크래핑 한것을 > '삼성전자 엑셀 파일' 로 저장하기
# 위의 결과를 응용해서 > '삼성전자' 뉴스 스크래핑 한것을 > '삼성전자 엑셀 파일' 로 저장하기
import requests # 요청해서 삼형제 가져오는 라이브러리
from bs4 import BeautifulSoup # 가져온 삼형제를 분석 가능한걸로 만들기 위한 라이브러리
from openpyxl import Workbook # 엑셀 파일 만들기 위한 라이브러리
from datetime import datetime # 날짜 가져오기 위한 라이브러리
def get_news(keyword):
wb= Workbook() # openpyxl 라이브러리 中 Workbook 함수?클래스? 를 > wb 라고 부를거야
sheet = wb.active # wb 中 active 함수를 > sheet 에 담아 (❓ 담아? 함수를? )
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# headers 는 모르겠네 😥😥❓❓
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
# 내가 특정 주소의 keyword 를 넣으면 > 해당 주소에 대한 keyword 에 대해서 'HTML, CSS, Javascript' 를 요청❓ > 이걸 get 해 > 그리고 data 에 담아
soup = BeautifulSoup(data.text, 'html.parser') # 받아온 data 에서 text 만 꺼내❓ > html 로 분석할 수 있게 해❓ > 그걸 soup 에 담아
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
# 분석할 수 있는 soup 에 > select 함수를 넣어서 분석하고 싶은 애들 css selector 로 골라와 > 그리고 lis 에 넣어
# 이제 그러면 lis 에는 li 들이 리스트 형태로, 덩어리 째로 들어가게 됨 ⭐⭐⭐⭐⭐
# [생각] li 까지 내려갔을 때 > li 들이, 리스트로 있어서, for 문을 쓸 수 있다는게 중요. / 아직 100% 이해는 안 돼 📛 /
# for 문 사용해서 가져오기
for li in lis: # li 리스트 덩어리 중 > 하나씩 꺼내올거야
a = li.select_one('a.news_tit') # 하나 꺼내온 li 에서 > class 이름이 new_tit 인것을 찾아서 > 그 부분을 a 에 담아
row = [a.text, a['href']] # a 중에서 text, 링크 주소를 꺼내줘 > 이걸 리스트에 담아 / ⭐ 이 부분이 바뀌었음
sheet.append(row) # row 를 line9 에서 만들어진 sheet 에 붙여넣는다. ⭐⭐⭐
# 위에는 print 를 했는데, 여기가 'excel' 에 넣는 순간임 ⭐⭐⭐
today = datetime.today().strftime("%Y_%m_%d") # 오늘 날짜 가져와서 > string 으로 바꾸고 > today 에 넣어
wb.save(f'{today}_{keyword}.xlsx') # 지금까지 만들어진걸 excel로 만든다.
# 30 line 에서 만든 날짜를 > f-string 으로 넣기
# ✅ 함수 인자 넣어줌
wb.close() # 종료❓ / 왜 있는지는 모르겠음.
get_news ('삼성전자') # 만든 함수 실행
get_news ('현대자동차')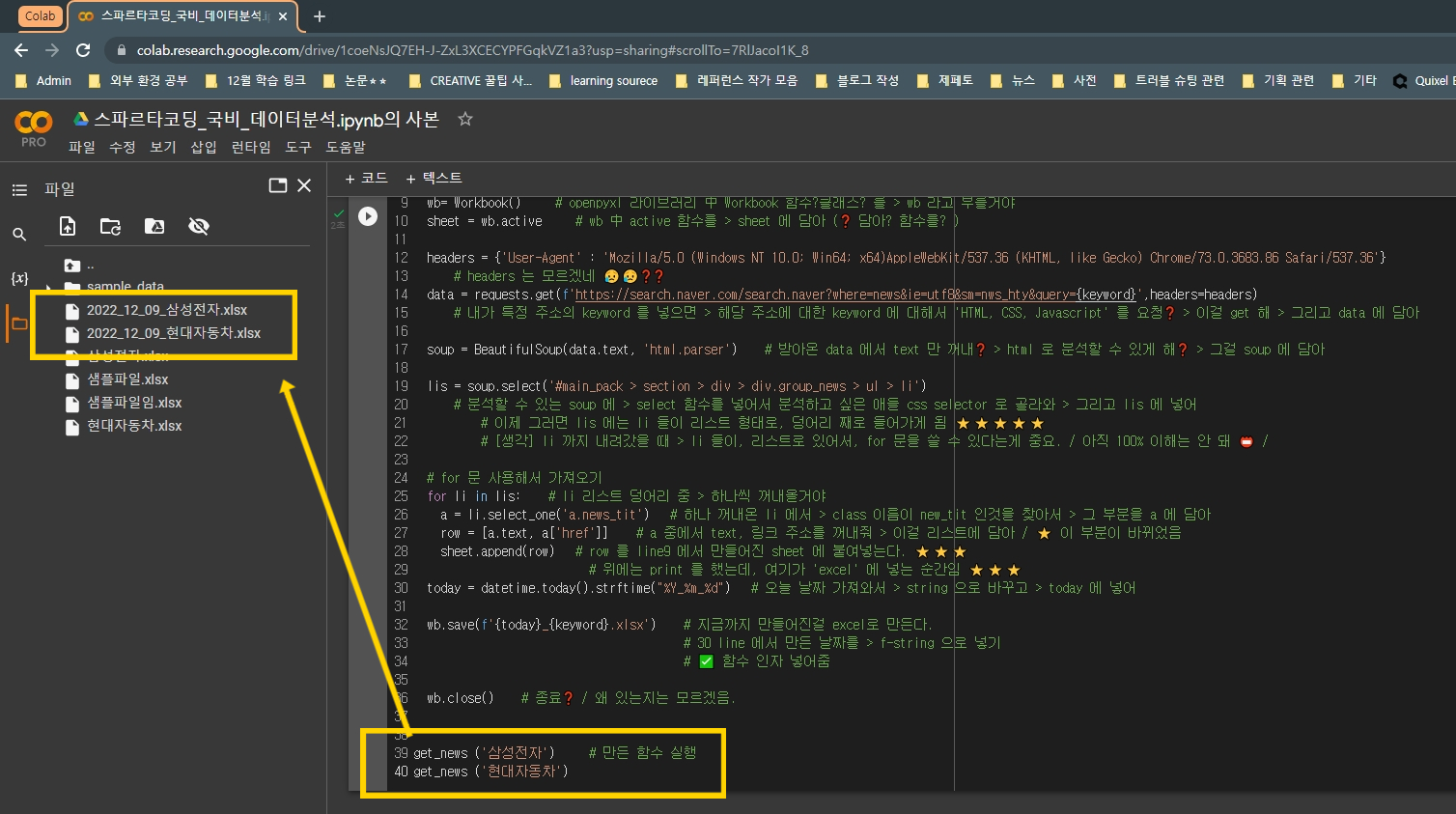
⭐⭐⭐ news 폴더에 쌓이게 하기
# news 라는 폴더! 에 쌓이게 하기!
import requests # 요청해서 삼형제 가져오는 라이브러리
from bs4 import BeautifulSoup # 가져온 삼형제를 분석 가능한걸로 만들기 위한 라이브러리
from openpyxl import Workbook # 엑셀 파일 만들기 위한 라이브러리
from datetime import datetime # 날짜 가져오기 위한 라이브러리
def get_news(keyword):
wb= Workbook() # openpyxl 라이브러리 中 Workbook 함수?클래스? 를 > wb 라고 부를거야
sheet = wb.active # wb 中 active 함수를 > sheet 에 담아 (❓ 담아? 함수를? )
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# headers 는 모르겠네 😥😥❓❓
data = requests.get(f'https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query={keyword}',headers=headers)
# 내가 특정 주소의 keyword 를 넣으면 > 해당 주소에 대한 keyword 에 대해서 'HTML, CSS, Javascript' 를 요청❓ > 이걸 get 해 > 그리고 data 에 담아
soup = BeautifulSoup(data.text, 'html.parser') # 받아온 data 에서 text 만 꺼내❓ > html 로 분석할 수 있게 해❓ > 그걸 soup 에 담아
lis = soup.select('#main_pack > section > div > div.group_news > ul > li')
# 분석할 수 있는 soup 에 > select 함수를 넣어서 분석하고 싶은 애들 css selector 로 골라와 > 그리고 lis 에 넣어
# 이제 그러면 lis 에는 li 들이 리스트 형태로, 덩어리 째로 들어가게 됨 ⭐⭐⭐⭐⭐
# [생각] li 까지 내려갔을 때 > li 들이, 리스트로 있어서, for 문을 쓸 수 있다는게 중요. / 아직 100% 이해는 안 돼 📛 /
# for 문 사용해서 가져오기
for li in lis: # li 리스트 덩어리 중 > 하나씩 꺼내올거야
a = li.select_one('a.news_tit') # 하나 꺼내온 li 에서 > class 이름이 new_tit 인것을 찾아서 > 그 부분을 a 에 담아
row = [a.text, a['href']] # a 중에서 text, 링크 주소를 꺼내줘 > 이걸 리스트에 담아 / ⭐ 이 부분이 바뀌었음
sheet.append(row) # row 를 line9 에서 만들어진 sheet 에 붙여넣는다. ⭐⭐⭐
# 위에는 print 를 했는데, 여기가 'excel' 에 넣는 순간임 ⭐⭐⭐
today = datetime.today().strftime("%Y_%m_%d") # 오늘 날짜 가져와서 > string 으로 바꾸고 > today 에 넣어
wb.save(f'news/{today}_{keyword}.xlsx') # 지금까지 만들어진걸 excel로 만든다.
# 30 line 에서 만든 날짜를 > f-string 으로 넣기
# ✅ 함수 인자 넣어줌
# ✅ 여기에 news 폴더 만들어줌 / news 를 여기에 쓰면 왜 폴더가 만들어지는 건지는 아직 모르겠음. 📛
wb.close() # 종료❓ / 왜 있는지는 모르겠음.
get_news ('삼성전자') # 만든 함수 실행
get_news ('현대자동차')
이전 스파르타 코딩 클럽 수업
| 강의 URL | https://bit.ly/3W2CYsK |
| Colab URL | https://bit.ly/3Ph9e9p |
728x90
반응형
'[WEB & AI] (feat. 취준) > Python' 카테고리의 다른 글
'[WEB & AI] (feat. 취준)/Python' Related Articles
more




Comments